現在、カードゲーム(トランプでなくTCGっぽいもの)を作成していますが、一番悩ましいところが敵AIの作成部分です。
プレイヤーと敵のカードパワーは同じくらいにしたいのですが、敵はプレイヤーと比較すると無駄な行動をするので、間違いなくヌルゲーになってしまいます。
自分の知識程度で、完全に最適化するのは難しいと思うので、プレイヤー有利になってしまうのは仕方ないと思います。
ただ、プレイヤーが「楽勝すぎてマジつまらん」と思わないために、少しは敵AIを作り込む必要があります。
実装しようとしている内容の設計部分について記載をしてみたいと思います。
評価の基準を決定する
まずAIを作成するに当たり、評価の基準を決定する必要があります。
例として以下の場合を考えます。

敵の場に、「HP5、攻撃力5」、「HP4、攻撃力4」、「HP3、攻撃力5」の3枚のカード
自分の場に、「HP3、攻撃力3」、「HP5、攻撃力4」の2枚のカードがあると仮定します。
そして敵カードを攻撃すると、敵カードからも反撃されるというルールにします。(シャドバやハースストーンと同じ感じです。)
この場合の評価の重みとしては
- 敵カードを倒す>味方カードが死ぬ
- 味方カードが死ぬ>敵カードが死なない(ダメージは受ける)
- 強い敵カードを倒す>弱い敵カードを倒す
- 弱い味方カードが死ぬ>強い味方カードが死ぬ
となるかなと思います。
敵カード撃破が味方カード死亡より重みが大きいのは、敵が生きていると、相手ターンに自由に使われてしまうためです。
具体的に評価の重みを考えると以下くらいが適当かなあと考えます。
敵カードを倒す:+(敵カード攻撃力+1)×3
味方カードが死ぬ:ー(味方カード攻撃力+1)
敵カードにダメージを与える(倒せない):+(与ダメージ+2)
攻撃力0の場合に変な動きになりそうなので、攻撃力+1することにしました。
上記は記事を書きながら適当に決めたので最適ではないと思いますが、評価軸を決めないと何も出来ないので、「駄目なら直せばいい」の精神で次に進みます。
シミュレーションを行い最適行動を導く
色々と調べましたが、カードゲームAIだと「実際に行動してどうなるか」で愚直に評価するのが一番良さそうでした。
オセロなどのボードゲームだと、更に相手の手を読むとか考えないといけないですが、手札が見えないカードゲームだとそこはどうせ難しいので、自ターンだけ考えればいいです。
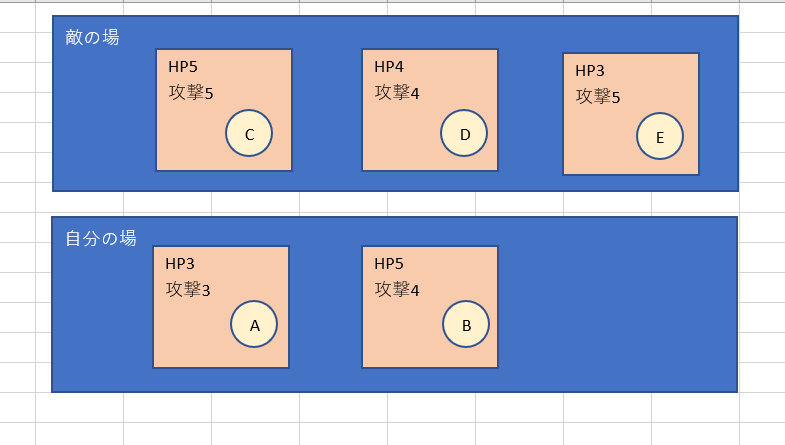
上記画像のようにカードにA~Eという番号を振りました。
ここから、攻撃のパターンは何があるか考えてみると
- A→C、B→C
- A→C、B→D
- A→C、B→E
- A→D、B→C
- A→D、B→D
- A→D、B→E
- A→E、B→C
- A→E、B→D
の8パターンになります。それぞれの先程の評価に従って評価値を算出してみると
- 6×3 – 4 – 3 = 11
- 5 + 5×3 – 4 = 16
- 5 + 6×3 – 4 – 5 = 12
- 5 + 6 – 4 – 3 = 4
- 5×3 – 4 – 3 = 8
- 6×3 + 5 – 4 – 3 = 16
- 6×3 + 6 – 4 – 3 = 17
- 6×3 + 5×3 – 3 = 30
となります。一番評価が高いのが8のパターン、一番評価が低いのが4のパターンです。
実際にどのような盤面になっているかを見ると
一番評価が高い8のパターン

一番評価が低い4のパターン
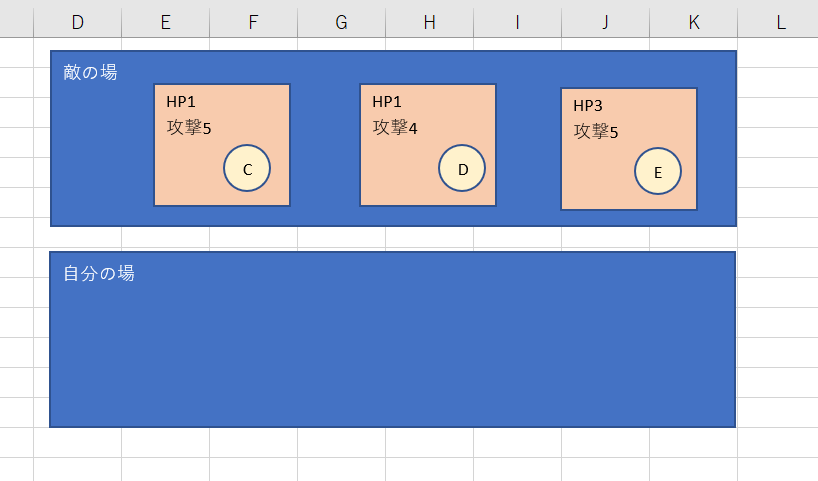
明らかに8のパターンのほうが良いので、評価はある程度妥当であることがわかります。
ここでうまく行かないようであれば評価の重みを見直します。
実際にどのようなロジックとすべきか
AIの方針は出来たものの、どう実装すればいいのかは悩みどころです。
というのも今回の例では8パターンしかなかったのですが、敵の場に5枚、味方の場に5枚のカードがあった場合には5の階乗通りのパターンがあります。
5! = 5 × 4 × 3 × 2 × 1 = 120通り
120通りくらい計算させればいいだろうと思うかもしれませんが、仮にカードが敵プレイヤーを攻撃できるとなれば、更に増えて6の階乗になります。
更に手札をどの様に切るか?、特殊能力でどの対象を選ぶか?などの要素が入ってくれば収集がつかなくなります。
そこで、個人開発レベルでは、「とりあえずランダムに100通り試して一番評価が高いものを採用する」でよいかなあと思いました。
それで駄目なら、重くならない程度に試行回数を増やします。
ランダムで行動させる際に、行動させた順番などを配列に保持しておき、評価後にその手順を再現します。
敵ターンにプレイヤーの行動が入ったときは再評価する
遊戯王のトラップカードみたいに、敵ターンに割り込みが入った時には、その効果が終わったタイミングで再評価するしか無いかなあと思います。
その効果によって、状況が一転してしまえば、前に実施した手順が最適ではなくなってしまいますからね。

コメント